Tutorial
This tutorial demonstrates a simple application of BAT.jl: A Bayesian fit of a histogram with two Gaussian peaks.
You can also download this tutorial as a Jupyter notebook and a plain Julia source file.
Table of contents:
Note: This tutorial is somewhat verbose, as it aims to be easy to follow for users who are new to Julia. For the same reason, we deliberately avoid making use of Julia features like closures, anonymous functions, broadcasting syntax, performance annotations, etc.
Input Data Generation
First, let's generate some synthetic data to fit. We'll need the Julia standard-library packages "Random", "LinearAlgebra" and "Statistics", as well as the packages "Distributions" and "StatsBase":
using Random, LinearAlgebra, Statistics, Distributions, StatsBaseAs the underlying truth of our input data/histogram, let us choose the expected count to follow the sum of two Gaussian peaks with peak areas of 500 and 1000, a mean of -1.0 and 2.0 and a standard error of 0.5. Then
data = vcat(
rand(Normal(-1.0, 0.5), 500),
rand(Normal( 2.0, 0.5), 1000)
)1500-element Vector{Float64}:
-1.664758129429425
-1.370904513873507
-1.5811347466525112
-1.4488716689149184
-1.5751417471167823
-0.7149138311702915
-1.0437086116253569
0.05986881125493304
-1.813187984470253
-0.7554593029221012
⋮
1.7046683773345923
1.462830752701928
2.7282123566458583
2.3740777241384285
2.1070761694562035
2.4099197005675217
1.2124250371765117
2.3434495538257685
2.3332686160255136resulting in a vector of floating-point numbers:
typeof(data) == Vector{Float64}trueNext, we'll create a histogram of that data, this histogram will serve as the input for the Bayesian fit:
hist = append!(Histogram(-2:0.1:4), data)StatsBase.Histogram{Int64, 1, Tuple{StepRangeLen{Float64, Base.TwicePrecision{Float64}, Base.TwicePrecision{Float64}, Int64}}}
edges:
-2.0:0.1:4.0
weights: [9, 10, 8, 21, 22, 27, 37, 31, 33, 44 … 15, 5, 5, 3, 2, 3, 0, 0, 0, 0]
closed: left
isdensity: falseUsing the Julia "Plots" package
using Plotswe can plot the histogram:
plot(
normalize(hist, mode=:density),
st = :steps, label = "Data",
title = "Data"
)
savefig("tutorial-data.pdf")
Let's define our fit function - the function that we expect to describe the data histogram, at each x-Axis position x, depending on a given set p of model parameters:
function fit_function(p::NamedTuple{(:a, :mu, :sigma)}, x::Real)
p.a[1] * pdf(Normal(p.mu[1], p.sigma), x) +
p.a[2] * pdf(Normal(p.mu[2], p.sigma), x)
endThe fit parameters (model parameters) a (peak areas) and mu (peak means) are vectors, parameter sigma (peak width) is a scalar, we assume it's the same for both Gaussian peaks.
The true values for the model/fit parameters are the values we used to generate the data:
true_par_values = (a = [500, 1000], mu = [-1.0, 2.0], sigma = 0.5)Let's visually compare the histogram and the fit function, using these true parameter values, to make sure everything is set up correctly:
plot(
normalize(hist, mode=:density),
st = :steps, label = "Data",
title = "Data and True Statistical Model"
)
plot!(
-4:0.01:4, x -> fit_function(true_par_values, x),
label = "Truth"
)
savefig("tutorial-data-and-truth.pdf")
Bayesian Fit
Now we'll perform a Bayesian fit of the generated histogram, using BAT, to infer the model parameters from the data histogram.
In addition to the Julia packages loaded above, we need BAT itself, as well as IntervalSets:
using BAT, DensityInterface, IntervalSetsLikelihood Definition
First, we need to define the likelihood for our problem.
BAT expects likelihoods to implements the DensityInterface API. We can simply wrap a log-likelihood function with DensityInterface.logfuncdensity to make it compatible.
For performance reasons, functions should [not access global variables directly] (https://docs.julialang.org/en/v1/manual/performance-tips/index.html#Avoid-global-variables-1). So we'll use an anonymous function inside of a let-statement to capture the value of the global variable hist in a local variable h (and to shorten function name fit_function to f, purely for convenience). DensityInterface.logfuncdensity then turns the log-likelihood function into a DensityInterface density object.
likelihood = let h = hist, f = fit_function
# Histogram counts for each bin as an array:
observed_counts = h.weights
# Histogram binning:
bin_edges = h.edges[1]
bin_edges_left = bin_edges[1:end-1]
bin_edges_right = bin_edges[2:end]
bin_widths = bin_edges_right - bin_edges_left
bin_centers = (bin_edges_right + bin_edges_left) / 2
logfuncdensity(function (params)
# Log-likelihood for a single bin:
function bin_log_likelihood(i)
# Simple mid-point rule integration of fit function `f` over bin:
expected_counts = bin_widths[i] * f(params, bin_centers[i])
# Avoid zero expected counts for numerical stability:
logpdf(Poisson(expected_counts + eps(expected_counts)), observed_counts[i])
end
# Sum log-likelihood over bins:
idxs = eachindex(observed_counts)
ll_value = bin_log_likelihood(idxs[1])
for i in idxs[2:end]
ll_value += bin_log_likelihood(i)
end
return ll_value
end)
endLogFuncDensity(Main.var"#5#6"{StepRangeLen{Float64, Base.TwicePrecision{Float64}, Base.TwicePrecision{Float64}, Int64}, StepRangeLen{Float64, Base.TwicePrecision{Float64}, Base.TwicePrecision{Float64}, Int64}, Vector{Int64}, typeof(Main.fit_function)}(-1.95:0.1:3.95, StepRangeLen(0.1, 0.0, 60), [9, 10, 8, 21, 22, 27, 37, 31, 33, 44 … 15, 5, 5, 3, 2, 3, 0, 0, 0, 0], Main.fit_function))BAT makes use of Julia's parallel programming facilities if possible, e.g. to run multiple Markov chains in parallel. Therefore, log-likelihood (and other) code must be thread-safe. Mark non-thread-safe code with @critical (provided by Julia package ParallelProcessingTools).
Support for automatic parallelization across multiple (local and remote) Julia processes is planned, but not implemented yet.
Note that Julia currently starts only a single thread by default. Set the the environment variable JULIA_NUM_THREADS to specify the desired number of Julia threads.
We can evaluate likelihood, e.g. at the true parameter values:
logdensityof(likelihood, true_par_values)-151.45377807651045Prior Definition
Next, we need to choose a sensible prior for the fit:
prior = distprod(
a = [Weibull(1.1, 5000), Weibull(1.1, 5000)],
mu = [-2.0..0.0, 1.0..3.0],
sigma = Weibull(1.2, 2)
)BAT supports most Distributions.Distribution types, and combinations of them, as priors.
Bayesian Model Definition
Given the likelihood and prior definition, a BAT.PosteriorMeasure is simply defined via
posterior = PosteriorMeasure(likelihood, prior)Parameter Space Exploration via MCMC
We can now use Markov chain Monte Carlo (MCMC) to explore the space of possible parameter values for the histogram fit.
To increase the verbosity level of BAT logging output, you may want to set the Julia logging level for BAT to debug via bat_logdebug().
Now we can generate a set of MCMC samples via bat_sample. We'll use 4 MCMC chains with 10^5 MC steps in each chain (after tuning/burn-in):
samples = bat_sample(posterior, TransformedMCMC(proposal = RandomWalk(), nsteps = 10^5, nchains = 4)).result[ Info: Setting new default BAT context BATContext{Float64}(Random123.Philox4x{UInt64, 10}(0xc93fe738c62bfa87, 0xe5faacaeaef77b0f, 0xb73c66ff539b9116, 0x846bccabcff1440c, 0xa1891935e17c8243, 0x9cc8ddb274716ba1, 0x0000000000000000, 0x0000000000000000, 0x0000000000000000, 0x0000000000000000, 0), HeterogeneousComputing.CPUnit(), ADTypes.NoAutoDiff())
[ Info: MCMCChainPoolInit: trying to generate 4 viable MCMC chain state(s).
[ Info: Selected 4 MCMC chain state(s).
[ Info: Begin tuning of 4 MCMC chain(s).
[ Info: MCMC Tuning cycle 1 finished, 4 chains, 1 tuned, 0 converged.
[ Info: MCMC Tuning cycle 2 finished, 4 chains, 4 tuned, 4 converged.
[ Info: MCMC tuning of 4 chains successful after 2 cycle(s).
[ Info: Running post-tuning stabilization steps for 4 MCMC chain(s).
[ Info: Generate main samples using 4 MCMC chain(s).Let's calculate some statistics on the posterior samples:
println("Truth: $true_par_values")
println("Mode: $(mode(samples))")
println("Mean: $(mean(samples))")
println("Stddev: $(std(samples))")Truth: (a = [500, 1000], mu = [-1.0, 2.0], sigma = 0.5)
Mode: (a = [500.0491342821723, 1002.5282290487556], mu = [-1.0028626124913171, 2.024257825577606], sigma = 0.5207615596366968)
Mean: (a = [503.14101193152453, 1000.9487014749084], mu = [-1.0030770377350968, 2.022727448775601], sigma = 0.5216627090167071)
Stddev: (a = [22.668145339836055, 31.89417249753069], mu = [0.026281416906266758, 0.01665190060553817], sigma = 0.010453881446198503)Internally, BAT often needs to represent variates as flat real-valued vectors:
unshaped_samples, f_flatten = bat_transform(Vector, samples)(result = DensitySampleVector(length = 94038, varshape = ValueShapes.ArrayShape{Float64, 1}((5,))), f_transform = Base.Fix2{typeof(ValueShapes.unshaped), ValueShapes.NamedTupleShape{(:a, :mu, :sigma), Tuple{ValueShapes.ValueAccessor{ValueShapes.ArrayShape{Real, 1}}, ValueShapes.ValueAccessor{ValueShapes.ArrayShape{Real, 1}}, ValueShapes.ValueAccessor{ValueShapes.ScalarShape{Real}}}, NamedTuple}}(ValueShapes.unshaped, NamedTupleShape((a = ValueShapes.ArrayShape{Real, 1}((2,)), mu = ValueShapes.ArrayShape{Real, 1}((2,)), sigma = ValueShapes.ScalarShape{Real}()))), optargs = (algorithm = BAT.UnshapeTransformation(), context = BATContext{Float64}(Random123.Philox4x{UInt64, 10}(0x240639a053b576ec, 0xd47dfc574837c94f, 0x027d6dce726926cf, 0x33832e7d37956919, 0xa1891935e17c8243, 0x9cc8ddb274716ba1, 0x0000000000000000, 0x0000000000000000, 0x0000000000000000, 0x8000020100000000, 0), HeterogeneousComputing.CPUnit(), ADTypes.NoAutoDiff())))The statisics above (mode, mean and std-dev) are presented in shaped form. However, it's not possible to represent statistics with matrix shape, e.g. the parameter covariance matrix, this way. So the covariance has to be accessed in unshaped form:
par_cov = cov(unshaped_samples)
println("Covariance: $par_cov")Covariance: [513.8448131479287 1.3772943087190328 -0.04259666717407655 0.0022222866491321963 0.014256966707448072; 1.3772943087190328 1017.2382393022413 -0.008593068821640118 -0.008800574879058828 -0.0011524313537985124; -0.04259666717407655 -0.008593068821640118 0.0006907128746009975 1.3455350781846962e-5 -4.083372711349178e-5; 0.0022222866491321963 -0.008800574879058828 1.3455350781846962e-5 0.00027728579377671986 -1.243656850311267e-6; 0.014256966707448072 -0.0011524313537985124 -4.083372711349178e-5 -1.243656850311267e-6 0.0001092836372911727]Use LazyReports.lazyreport to generate an overview of the sampling result and parameter estimates (based on the marginal distributions):
using LazyReports
lazyreport(samples)Sampling result
Total number of samples: 94038
Total weight of samples: 400000
Effective sample size: between 12741 and 14212
Marginals
| Parameter | Mean | Std. dev. | Gobal mode | Marg. mode | Cred. interval | Histogram |
|---|---|---|---|---|---|---|
| a[1] | 503.141 | 22.6681 | 500.049 | 510.0 | 479.405 .. 524.618 | 413[[603 |
| a[2] | 1000.95 | 31.8942 | 1002.53 | 1010.0 | 967.412 .. 1031.25 | 869[[1.12e+03 |
| mu[1] | -1.00308 | 0.0262814 | -1.00286 | -1.01 | -1.02825 .. -0.975292 | -1.12[[-0.899 |
| mu[2] | 2.02273 | 0.0166519 | 2.02426 | 2.025 | 2.00692 .. 2.04013 | 1.95[[2.09 |
| sigma | 0.521663 | 0.0104539 | 0.520762 | 0.525 | 0.510685 .. 0.531575 | 0.479[[0.569 |
Visualization of Results
BAT.jl comes with an extensive set of plotting recipes for ["Plots.jl"] (http://docs.juliaplots.org/latest/). We can plot the marginalized distribution for a single parameter (e.g. parameter 3, i.e. μ[1]):
plot(
samples, :(mu[1]),
mean = true, std = true, globalmode = true, marginalmode = true,
nbins = 50, title = "Marginalized Distribution for mu[1]"
)
savefig("tutorial-single-par.pdf")
or plot the marginalized distribution for a pair of parameters (e.g. parameters 3 and 5, i.e. μ[1] and σ), including information from the parameter stats:
plot(
samples, (:(mu[1]), :sigma),
mean = true, std = true, globalmode = true, marginalmode = true,
nbins = 50, title = "Marginalized Distribution for mu[1] and sigma"
)
plot!(BAT.MCMCBasicStats(samples), (3, 5))
savefig("tutorial-param-pair.png")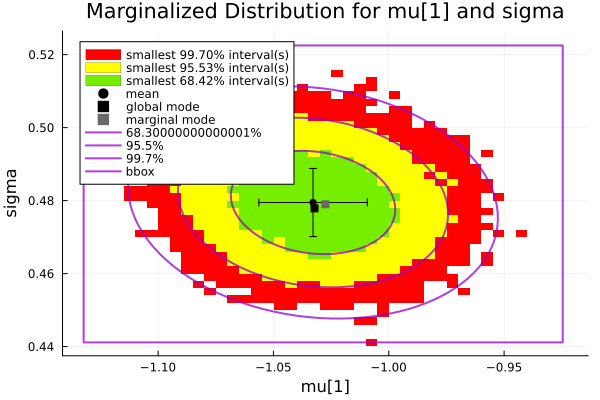
We can also create an overview plot of the marginalized distribution for all pairs of parameters:
plot(
samples,
mean = false, std = false, globalmode = true, marginalmode = false,
nbins = 50
)
savefig("tutorial-all-params.png")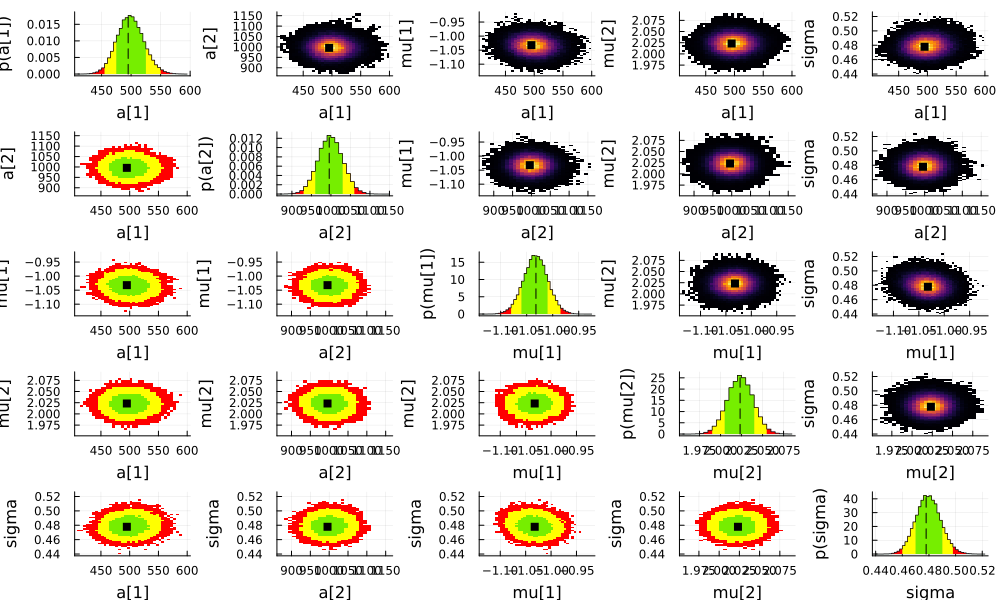
Integration with Tables.jl
DensitySamplesVector supports the Tables.jl interface, so it is a table itself. We can also convert it to other table types, e.g. a TypedTables.Table:
using TypedTables
tbl = Table(samples)Table with 5 columns and 94038 rows:
v logd weight info aux
┌──────────────────────────────────────────────────────────────────────────
1 │ (a = [577.726, 1049.3… -176.163 1 MCMCSampleID(8, 1, 6,… nothing
2 │ (a = [573.932, 1038.4… -175.792 1 MCMCSampleID(8, 1, 6,… nothing
3 │ (a = [572.223, 1026.3… -176.351 1 MCMCSampleID(8, 1, 6,… nothing
4 │ (a = [564.381, 1015.5… -175.319 1 MCMCSampleID(8, 1, 6,… nothing
5 │ (a = [579.098, 987.90… -175.105 1 MCMCSampleID(8, 1, 6,… nothing
6 │ (a = [575.251, 963.88… -174.54 2 MCMCSampleID(8, 1, 6,… nothing
7 │ (a = [531.957, 983.09… -174.387 6 MCMCSampleID(8, 1, 6,… nothing
8 │ (a = [535.655, 980.52… -172.588 1 MCMCSampleID(8, 1, 6,… nothing
9 │ (a = [511.211, 996.10… -170.152 1 MCMCSampleID(8, 1, 6,… nothing
10 │ (a = [505.902, 997.72… -170.073 1 MCMCSampleID(8, 1, 6,… nothing
11 │ (a = [487.948, 989.07… -170.499 4 MCMCSampleID(8, 1, 6,… nothing
12 │ (a = [506.064, 982.65… -171.446 6 MCMCSampleID(8, 1, 6,… nothing
13 │ (a = [527.823, 981.64… -171.459 2 MCMCSampleID(8, 1, 6,… nothing
14 │ (a = [541.763, 1001.7… -172.521 1 MCMCSampleID(8, 1, 6,… nothing
15 │ (a = [538.284, 987.04… -171.791 13 MCMCSampleID(8, 1, 6,… nothing
16 │ (a = [515.108, 976.84… -170.326 3 MCMCSampleID(8, 1, 6,… nothing
17 │ (a = [484.079, 1001.6… -168.873 2 MCMCSampleID(8, 1, 6,… nothing
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮or a DataFrames.DataFrame, etc.
Comparison of Truth and Best Fit
As a final step, we retrieve the parameter values at the mode, representing the best-fit parameters
samples_mode = mode(samples)(a = [500.0491342821723, 1002.5282290487556], mu = [-1.0028626124913171, 2.024257825577606], sigma = 0.5207615596366968)Like the samples themselves, the result can be viewed in both shaped and unshaped form. samples_mode is presented as a 0-dimensional array that contains a NamedTuple, this representation preserves the shape information:
samples_mode isa NamedTupletruesamples_mode is only an estimate of the mode of the posterior distribution. It can be further refined using bat_findmode:
using Optim
findmode_result = bat_findmode(
posterior,
OptimAlg(optalg = Optim.NelderMead(), init = ExplicitInit([samples_mode]))
)
fit_par_values = findmode_result.result(a = [501.6587177539811, 1000.1148651482343], mu = [-1.0024892500775149, 2.0228295817679802], sigma = 0.5204978642887566)Let's plot the data and fit function given the true parameters and MCMC samples
plot(-4:0.01:4, fit_function, samples)
plot!(
normalize(hist, mode=:density),
color=1, linewidth=2, fillalpha=0.0,
st = :steps, fill=false, label = "Data",
title = "Data, True Model and Best Fit"
)
plot!(-4:0.01:4, x -> fit_function(true_par_values, x), color=4, label = "Truth")
savefig("tutorial-data-truth-bestfit.pdf")
Fine-grained control
BAT provides fine-grained control over the MCMC algorithm options, the MCMC chain initialization, tuning/burn-in strategy and convergence testing. All option value used in the following are the default values, any or all may be omitted.
We'll sample using the random-walk Metropolis-Hastings MCMC algorithm:
mcmcalgo = RandomWalk()RandomWalk{Float64, Tuple{Float64, Float64}, Distributions.TDist{Float64}}
target_acceptance: Float64 0.234
target_acceptance_int: Tuple{Float64, Float64}
proposaldist: Distributions.TDist{Float64}
BAT requires a counter-based random number generator (RNG), since it partitions the RNG space over the MCMC chains. This way, a single RNG seed is sufficient for all chains and results are reproducible even under parallel execution. By default, BAT uses a Philox4x RNG initialized with a random seed drawn from the system entropy pool:
using Random123
rng = Philox4x()
context = BATContext(rng = Philox4x())By default, RandomWalk() uses the following options.
For Markov chain initialization:
init = MCMCChainPoolInit()MCMCChainPoolInit
init_tries_per_chain: IntervalSets.ClosedInterval{Int64}
nsteps_init: Int64 1000
initval_alg: InitFromTarget InitFromTarget()
strict: Bool true
For the MCMC burn-in procedure:
burnin = MCMCMultiCycleBurnin()MCMCMultiCycleBurnin
nsteps_per_cycle: Int64 10000
max_ncycles: Int64 30
nsteps_final: Int64 1000
For convergence testing:
convergence = BrooksGelmanConvergence()BrooksGelmanConvergence
threshold: Float64 1.1
corrected: Bool false
To generate MCMC samples with explicit control over all options, use something like
samples = bat_sample(
posterior,
TransformedMCMC(
proposal = mcmcalgo,
nchains = 4,
nsteps = 10^5,
init = init,
burnin = burnin,
convergence = convergence,
strict = true,
store_burnin = false,
nonzero_weights = true,
callback = (x...) -> nothing
),
context
).result[ Info: MCMCChainPoolInit: trying to generate 4 viable MCMC chain state(s).
[ Info: Selected 4 MCMC chain state(s).
[ Info: Begin tuning of 4 MCMC chain(s).
[ Info: MCMC Tuning cycle 1 finished, 4 chains, 2 tuned, 0 converged.
[ Info: MCMC Tuning cycle 2 finished, 4 chains, 4 tuned, 4 converged.
[ Info: MCMC tuning of 4 chains successful after 2 cycle(s).
[ Info: Running post-tuning stabilization steps for 4 MCMC chain(s).
[ Info: Generate main samples using 4 MCMC chain(s).Saving result data to files
The package FileIO.jl(in conjunction with JLD2.jl) offers a convenient way to store results like posterior samples to file:
using FileIO
import JLD2
FileIO.save("results.jld2", Dict("samples" => samples))JLD2 persists the full information (including value shapes), so you can reload exactly the same data into memory in a new Julia session via
using FileIO
import JLD2
samples = FileIO.load("results.jld2", "samples")provided you use compatible versions of BAT and it's dependencies. Note that JLD2 is not a long-term stable file format. Also note that this functionality is provided by FileIO.jl and JLD2.jl and not part of the BAT API itself.
BAT.jl itself can write samples to standard HDF5 files in a form suitable for long-term storage (via HDF5.jl):
import HDF5
bat_write("results.h5", samples)The resulting files have an intuitive HDF5 layout and can be read with the standard HDF5 libraries, so they are easily accessible from other programming languages as well. Not all value shape information can be preserved, though. To read BAT.jl HDF5 sample data, use
using BAT
import HDF5
samples = bat_read("results.h5").resultBAT.jl's HDF5 file format may evolve over time, but future versions of BAT.jl will be able to read HDF5 sample data written by this version of BAT.jl.
This page was generated using Literate.jl.